

Develop a Basic Voice-to-Voice Translation Application Using Python


In this article, we will create a simple voice-to-voice translator application using Python. We will use Gradio for the interface, AssemblyAI for voice recognition, the translate library for text translation, and ElevenLabs for text-to-speech conversion.
Preparing the Environment
Before starting, make sure you have the required API keys and libraries. Create a .env file in the same folder as your project and save the API keys in this file. Do not forget to add .env to .gitignore if you plan to push your code to GitHub. To obtain the keys, first visit ElevenLabs and Assembly AI.
ELEVENLABS_API_KEY=your_elevenlabs_api_key
ASSEMBLYAI_API_KEY=your_assemblyai_api_key
Next, you also need to install the required libraries:
pip install gradio assemblyai translate elevenlabs python-dotenv
Importing Libraries and Loading Configuration
First, we import the necessary libraries and load the API keys from the .env file.
import uuid
import gradio as gr
import assemblyai as aai
from pathlib import Path
from dotenv import dotenv_values
from translate import Translator
from elevenlabs import VoiceSettings
from elevenlabs.client import ElevenLabs
We use gradio for the web interface, assemblyai for audio-to-text transcription, translate for text translation, and elevenlabs for text-to-speech conversion. We use uuid to generate unique file names, Path for file path handling, and dotenv_values to load the .env file.
After importing all the necessary libraries, we load the API keys from the .env file we created earlier:
config = dotenv_values(".env")
ELEVENLABS_API_KEY = config["ELEVENLABS_API_KEY"]
ASSEMBLYAI_API_KEY = config["ASSEMBLYAI_API_KEY"]
Audio Transcription
We use AssemblyAI to transcribe the audio file.
def audio_transcription(audio_file):
aai.settings.api_key = ASSEMBLYAI_API_KEY
transcriber = aai.Transcriber()
transcription = transcriber.transcribe(audio_file)
return transcription
First, we set the API key for AssemblyAI in aai.settings.api_key. Then, we initialize the transcriber aai.Transcriber and transcribe the provided audio file with transcribe.
Text Translation
In this function, we translate the transcribed text into Spanish, Arabic, and Japanese.
def text_translation(text):
translator_es = Translator(from_lang="en", to_lang="es")
es_text = translator_es.translate(text)
translator_ar = Translator(from_lang="en", to_lang="ar")
ar_text = translator_ar.translate(text)
translator_ja = Translator(from_lang="en", to_lang="ja")
ja_text = translator_ja.translate(text)
return es_text, ar_text, ja_text
First, we initialize translators for each target language using Translator. Next, we use the translate method to translate the text from English to the target languages.
Text to Speech
Finally, we use ElevenLabs to convert the translated text into speech.
def text_to_speech(text: str) -> str:
client = ElevenLabs(api_key=ELEVENLABS_API_KEY)
response = client.text_to_speech.convert(
voice_id="pNInz6obpgDQGcFmaJgB",
optimize_streaming_latency="0",
output_format="mp3_22050_32",
text=text,
model_id="eleven_multilingual_v2",
voice_settings=VoiceSettings(
stability=0.5,
similarity_boost=0.8,
style=0.5,
use_speaker_boost=True,
),
)
save_file_path = f"{uuid.uuid4()}.mp3"
with open(save_file_path, "wb") as f:
for chunk in response:
if chunk:
f.write(chunk)
print(f"{save_file_path}: A new audio file was saved successfully!")
return save_file_path
First, we initialize the client variable by calling the ElevenLabs class. Next, we use the text_to_speech.convert method to convert the text to speech with the specified parameters.
The voice_to_voice Function
This function is the core of our project. It transcribes the input audio, translates it into several languages, and converts the translations back into audio.
def voice_to_voice(audio_file):
transcription_response = audio_transcription(audio_file)
if transcription_response.status == aai.TranscriptStatus.error:
raise gr.Error(transcription_response.error)
else:
text = transcription_response.text
es_translation, ar_translation, ja_translation = text_translation(text)
es_audio_path = text_to_speech(es_translation)
ar_audio_path = text_to_speech(ar_translation)
ja_audio_path = text_to_speech(ja_translation)
es_path = Path(es_audio_path)
ar_path = Path(ar_audio_path)
ja_path = Path(ja_audio_path)
return es_path, ar_path, ja_path
The voice_to_voice function takes an audio file as a parameter and handles the entire process of transcription, translation, and text-to-speech conversion. The transcription_response variable stores the response from the transcription function. The transcribed audio is then translated into text in Spanish, Arabic, and Japanese. Once the translated text is obtained, it is converted back into speech.
Creating the User Interface
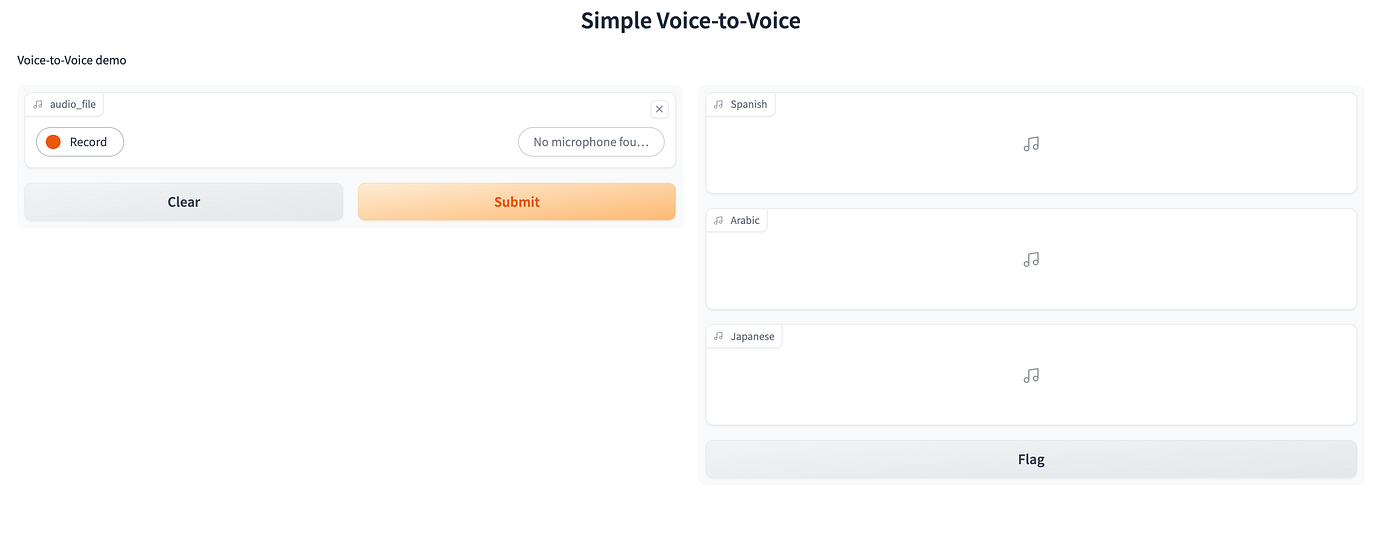
For this project, we use Gradio to create a simple, user-friendly interface. Here, users can input audio through their microphone and get the translated audio output.
audio_input = gr.Audio(
sources=["microphone"],
type="filepath"
)
demo = gr.Interface(
fn=voice_to_voice,
inputs=audio_input,
outputs=[gr.Audio(label="Spanish"), gr.Audio(label="Arabic"), gr.Audio(label="Japanese")],
title="Voice-to-Voice Translator",
description="Voice-to-Voice",
)
if __name__ == "__main__":
demo.launch()
First, we define the audio input source with gr.Audio. Then, with gr.Interface, we create the Gradio interface with the specified input and output.
Full main.py file
import gradio as gr
import assemblyai as aai
from translate import Translator
from elevenlabs import VoiceSettings
from elevenlabs.client import ElevenLabs
import uuid
from pathlib import Path
from dotenv import dotenv_values
config = dotenv_values(".env")
ELEVENLABS_API_KEY = config["ELEVENLABS_API_KEY"]
ASSEMBLYAI_API_KEY = config["ASSEMBLYAI_API_KEY"]
def voice_to_voice(audio_file):
transcription_response = audio_transcription(audio_file)
if transcription_response.status == aai.TranscriptStatus.error:
raise gr.Error(transcription_response.error)
else:
text = transcription_response.text
es_translation, ar_translation, ja_translation = text_translation(text)
es_audio_path = text_to_speech(es_translation)
ar_audio_path = text_to_speech(ar_translation)
ja_audio_path = text_to_speech(ja_translation)
es_path = Path(es_audio_path)
ar_path = Path(ar_audio_path)
ja_path = Path(ja_audio_path)
return es_path, ar_path, ja_path
def audio_transcription(audio_file):
aai.settings.api_key = ASSEMBLYAI_API_KEY
transcriber = aai.Transcriber()
transcription = transcriber.transcribe(audio_file)
return transcription
def text_translation(text):
translator_es = Translator(from_lang="en", to_lang="es")
es_text = translator_es.translate(text)
translator_ar = Translator(from_lang="en", to_lang="ar")
ar_text = translator_ar.translate(text)
translator_ja = Translator(from_lang="en", to_lang="ja")
ja_text = translator_ja.translate(text)
return es_text, ar_text, ja_text
def text_to_speech(text: str) -> str:
client = ElevenLabs(
api_key=ELEVENLABS_API_KEY,
)
# Calling the text_to_speech conversion API with detailed parameters
response = client.text_to_speech.convert(
voice_id="pNInz6obpgDQGcFmaJgB", # Adam pre-made voice
optimize_streaming_latency="0",
output_format="mp3_22050_32",
text=text,
model_id="eleven_multilingual_v2", # use the turbo model for low latency
voice_settings=VoiceSettings(
stability=0.5,
similarity_boost=0.8,
style=0.5,
use_speaker_boost=True,
),
)
# Generating a unique file name for the output MP3 file
save_file_path = f"{uuid.uuid4()}.mp3"
# Writing the audio to a file
with open(save_file_path, "wb") as f:
for chunk in response:
if chunk:
f.write(chunk)
print(f"{save_file_path}: A new audio file was saved successfully!")
# Return the path of the saved audio file
return save_file_path
audio_input = gr.Audio(
sources=["microphone"],
type="filepath"
)
demo = gr.Interface(
fn=voice_to_voice,
inputs=audio_input,
outputs=[gr.Audio(label="Spanish"), gr.Audio(label="Arabic"), gr.Audio(label="Japanese")],
title="Voice-to-Voice Translator",
description="Voice-to-Voice",
)
if __name__ == "__main__":
demo.launch()
credit https://blog.gopenai.com/create-a-simple-voice-to-voice-translation-app-with-python-83310c633a20